Privat benutze ich seit einer ganzen Weile primär FreeBSD und auch schon ewig benutze ich für die Benutzerauthentifizierung LDAP. Leider hatte Thunderbird mit genau dieser Konstellation Probleme und direkt beim Starten gab es einen Crash. Mit normalen lokalen Benutzern hingegen lief Thunderbird problemlos. Ich habe dazu auch ein paar Bug-Reports gefunden, die angeblich auch gefixt sind. Aber bis vor kurzem ging es definitiv noch nicht.
Aber jetzt habe ich es mal wieder getestet und siehe da, es funktioniert! Es geschehen offenbar doch noch Wunder.
Mal angenommen man hat eine Textdatei in XNEdit geöffnet, in der sich im Text eine URL befindet, die man bequem öffnen möchte. Zugegeben, die URL kopieren und im Browser öffnen ist jetzt nicht wahnsinnig schwierig, aber es geht minimal einfacher.
Die Idee ist ein kurzes Makro, welches den ausgewählten Text an xdg-open übergibt. Das Makro kann dann im Makro- oder Background-Menü hinterlegt werden (Preferences -> Default Settings -> Customize Menus).
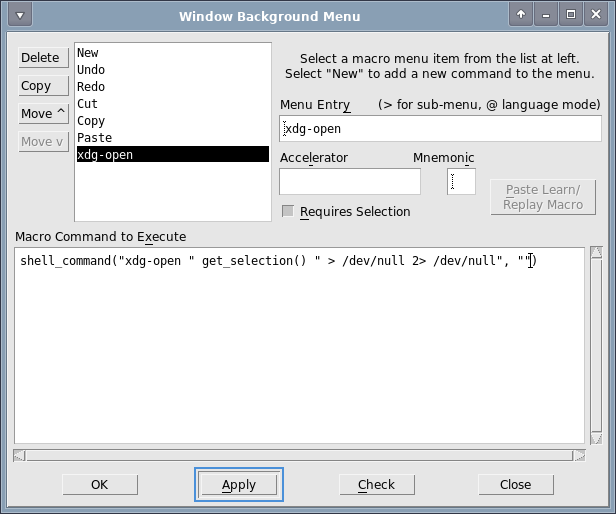
Macro Command:
shell_command("xdg-open " get_selection() " > /dev/null 2> /dev/null", "")
Wichtig ist, dass Requires Selection angekreuzt ist.
Danach reicht es die URL zu markieren und das Makro auszuführen (Rechtsklick für das Backgroundmenu oder man konfiguriert auch einen Accelerator). Das Ganze funktioniert nicht nur mit URLs, sondern mit allem, was von xdg-open geöffnet werden kann, z.B. auch Email-Adressen.
Im Gegensatz zu C++ oder vielen anderen Sprachen unterstützt C keine Default Values für Funktionsparameter. Auch ein Sprachkonstrukt wie Named Parameters, welches es z.B. in Python gibt, kennt C nicht.
Häufig wird als Workaround dafür Variadic Parameters verwendet, z.B. laut Linux-Manpage gibt es den open-Syscall in zwei Varianten:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
In Wahrheit sieht die Signatur allerdings so aus:
int open(const char *pathname, int flags, ...);
Das funktioniert grundsätzlich, hat jedoch den Nachteil, dass für alle zusätzlichen optionalen Parameter keine Typüberprüfung stattfindet.
Es gibt jedoch eine Alternative die sich Compound Literale für structs bemächtigt. Die Idee ist, dass alle Parameter an die Funktion per struct übergeben werden. Damit es wie ein normaler Funktionsaufruf aussieht, wird das ganze als Makro hübsch verpackt, welches die Makro-Parameter zu einem Compound Literal macht.
#include <stdio.h>
typedef struct {
int a;
int b;
int c;
} TestFuncArgs;
#define testfunc(...) testfunc_f((TestFuncArgs){ __VA_ARGS__})
void testfunc_f(TestFuncArgs args) {
printf("a: %d b: %d c: %d\n", args.a, args.b, args.c);
}
int main(int argc, char** argv) {
testfunc(1, 2, 3);
testfunc(4, 5);
testfunc(.a = 10, .c = 20);
//testfunc("hello"); //warning
return 0;
}
Hier findet für alle Parameter eine Typüberprüfung statt und zusätzlich gibt es auch die Option, Designated Initializers zu verwenden, daher anstatt die struct-Werte als einfache Liste in richtiger Reihenfolge anzugeben, kann auch einfach der Feldname angegeben werden.
Es gibt im Jahr 2021 absolut keinen Grund mehr, Latin-1 bzw. ISO 8859-1 und dergleichen zu benutzen. Verwendet gefälligst UTF-8 oder eine der anderen Kodierungen für Unicode. Wer noch Latin-1 oder ähnliches benutzt, der macht etwas falsch. Es gibt keinen Verwendungszweck dafür. Unicode wird dieses Jahr 30 Jahre alt. UTF-8 gibt es seit 1996. Unterstützung dafür gibt es in Betriebsystemen und Anwendersoftware dafür bestimmt seit 20 Jahren. Wenn irgendwelche Software heutzutage kein Unicode kann, dann ist das ein schwerwiegender Mangel. Wer auf solche Software angewiesen ist, der sollte sich mal nach Alternativen umsehen.
Es ist besorgniserregend, wie oft ich bei XNEdit irgendwelche Anfragen kriege, ob ich nicht irgendwelche Encoding-Features implementieren könnte. Zum Beispiel passt manchen Leuten offenbar UTF-8 als Default nicht. Auch wenn ich sowas jetzt immer implementiert habe, finde ich das einfach nur falsch. Einfach für alle Textdateien UTF-8 benutzen oder UTF-16 mit Byte Order Mark, wenn es sich anbietet.
Damit dies nicht ein völlig unkonstruktiver Rant ist, gibt es hier noch eine kleine Hilfe, um falsch kodierte Dateien zu finden.
find . -type f -name "*" -exec file --mime-encoding {} \; | grep -v "utf\|ascii\|binary"
Bei Bedarf statt * einen Filter einsetzen, damit nicht zu viele Dateien unnötig überprüft werden. Das ganze liefert euch eine Liste der Dateien, die ihr besser umkodieren solltet. Das Umkodieren macht dieser Oneliner jedoch nicht, das muss manuell oder mit einem extra Script gemacht werden, das ich jetzt hier nicht mitliefern wollte, da die Liste hoffentlich eh nur aus bedauerlichen Einzelfällen bestehen wird.
Finde den Syntax-Fehler in folgendem C-Code:
#include <stdio.h>
int main(int argc, char **argv) {
int a = 3;
switch(a) {
case 1:
printf("1\n");
break;
case 2:
printf("2\n");
int c2 = 0;
break;
case 3:
int c3 = 3;
printf("%d\n", c3);
break;
}
return 0;
}
Ein ähnlicher Fall wie hier im Beispiel hatte sich bei mir zugetragen. Der Compiler bemängelte die Variablendeklaration nach dem Case. Das heißt, hier im Beispiel ist die fehlerhafte Zeile die Variablendeklaration im Case 3.
Ich gebe zu, dass mich dies erstmal verwirrt hat und ich dachte, ich hätte versehentlich im C90-Modus kompiliert. Der Grund, wieso dies einen Fehler wirft, ist, dass ein Case nichts anderes als ein Label ist und Variablendeklarationen in C nicht mit einem Label versehen werden können.
Kommentare
dev | Artikel: Datei ver- und entschlüsseln mit openssl - kompatibel mit dav
Andreas | Artikel: Datenanalyse in der Shell Teil 1: Basis-Tools
Einfach und cool!
Danke Andreas
Rudi | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Damit wird Nedit durch XNedit ersetzt.
Danke!
Olaf | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Anti-Aliasing hängt von der Schriftart ab. Mit einem bitmap font sollte die Schrift klassisch wie in nedit aussehen.
Einfach unter Preferences -> Default Settings -> Text Fonts nach einer passenden Schriftart suchen.
Peter | Artikel: XNEdit - Mein NEdit-Fork mit Unicode-Support
Mettigel | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ich hatte gedacht, dass der GX-415 im s920 deutlich mehr Dampf hat als der Raspi4.
Mein Thinclient verbraucht mit 16 GB RAM ~11 W idle, das ist das Dreifache vom RP4. Das muss man dem kleinen echt lassen... Sparsam ist er.
Olaf | Artikel: Raspberry Pi1 vs Raspberry Pi4 vs Fujitsu s920 vs Sun Ultra 45
Ergebnisse von der Ultra 80 wären natürlich interessant, insbesondere im Vergleich mit dem rpi1.